- آموزش بازار سهام جهانی و بازارهای مالی
- کلیفورد شانس
- تجارت موقعیت چیست؟مزایا و مضرات تجارت موقعیت
- گزارش بازارهای جهانی - 1 مارس
- چگونه بدون پول یک کسب و کار راه اندازی کنیم
- بحث ناهار zew در بروکسل - موانع آشنا و رویکردهای جدید در سیاست جهانی آب و هوا
- بهترین سیگنال های رمزنگاری بیت کوین
- راهنمای ساده برای بهترین کیف پول Zcash در سال 2023
- tradergav. com
- Olymptrade - حساب نگهداری - پول متوقف ، ثبت نام

آخرین مطالب
امکانات وب


ادوارد لانسیاکس 1 *، نوئه چاگاسپانیان 1 و یواخیم فراموش 1،2
- 1 تغییرات جهانی، ژنو، سوئیس
- 2 Assemblée Nationale، پاریس، فرانسه
زمینه: نسل سوم ارزهای رمزنگاری شده، ارزهای رمزپایه ای را جمع آوری می کند که به اندازه بازار متنوع هستند (مثلاً Dogecoin یا Litecoin). در حالی که Dogecoin به عنوان یک memecoin در نظر گرفته می شود، دیگری دسته بسیار متفاوتی از سرمایه گذاران را جمع آوری می کند. تا آنجا که ما می دانیم، هیچ مطالعه ای به طور مستقل تأثیر اقتصادی جامعه رمزنگاری بر این ارزهای دیجیتال را ارزیابی نکرده است. علاوه بر این، احتمالات روش شناختی مختلفی برای پیش بینی قیمت ارزهای دیجیتال وجود دارد که عمدتاً از جوامع آنلاین می آیند.
روش: مطالعه ما به صورت گذشته نگر (از 01/01/2015 تا 03/11/2021) - با استفاده از داده های دسترسی باز - قدرت ارتباط (با استفاده از اطلاعات متقابل نرمال شده) و همبستگی خطی (با استفاده از همبستگی پیرسون) بین فعالیت توییتر و ارز دیجیتالویژگی های اقتصادیعلاوه بر این، ما مدل های مختلفی را محاسبه کرده ایم (ADF، ARIMA، و شبکه عصبی بازگشتی با حافظه کوتاه مدت چند متغیره تفسیرپذیر) که مقادیر قیمت گذشته را پیش بینی می کنند و دقت آن ها را ارزیابی می کنند.
یافته ها و نتیجه گیری: در حالی که میانگین ارزش تراکنش های Dogecoin تحت تأثیر توییت ها قرار می گیرد، توییت ها تحت تأثیر تعداد تراکنش های Litecoin و میانگین ارزش تراکنش های Litecoin هستند. تعداد توییت ها تحت تأثیر رفتار نهنگ دوج کوین قرار می گیرد، اما هیچ رابطه معنی داری بین نهنگ های لایت کوین و توییت ها یافت نشد. خطای پیش بینی حاصل از مدل های ARIMA (0،0،0) ما 0. 08٪ (با Litecoin) و 0. 22٪ (با Dogecoin) بود. بنابراین، اینها تازه آغاز یافته های علمی هستند که ممکن است بر اساس این نتایج منجر به ساخت یک ربات معامله گر شوند. با این حال، این مطالعه به خودی خود فقط برای بحث آکادمیک است و باید با تحقیقات بیشتر نتیجه گیری شود. در صورت انجام هرگونه سرمایه گذاری مالی بر اساس نتایج آن، نویسندگان نمی توانند مسئولیتی داشته باشند.
مقدمه
از زمان سفید بودن Satoshi Nakamoto در سال 2008 ، ارزهای رمزنگاری شده به یک سرمایه بزرگ در بازار افزایش یافته است - در حال حاضر بیش از 2 دلار (از دسامبر 2021). به نظر می رسد این افزایش عظیم سرمایه گذاری در بازار رمزنگاری ، در نگاه اول عمیقاً با جامعه رمزنگاری مرتبط است. در واقع ، بیشتر سکه ها دارای یک جامعه قوی هستند که آنها را از طریق شبکه های اجتماعی تبلیغ می کنند. یکی از مهمترین نمونه ها هنگام صحبت در مورد تبلیغات آنلاین سکه ، ممکن است توییت های الون مسک باشد. به نظر می رسید که وی تأثیر زیادی در بازار رمزنگاری دارد زیرا به نظر می رسد ارزش توییت افزایش یا کاهش می یابد ، که می تواند یک تأخیر خودی باشد. با این حال ، طبق یک مطالعه داده بزرگ (Tandon و همکاران ، 2021) ، به وضوح می توان اظهار داشت که الون ماسک نمی تواند دنیای بی ثبات ارزهای رمزنگاری شده و به ویژه بیت کوین و سگکوئین را کنترل کند.
اما قیمت cryptocurrency می تواند بیشتر از هر چیز دیگری توسط اثر لیندی هدایت شود. این نظریه بیان می کند که امید به زندگی آینده برخی از کالاهای غیر قابل فرکه-مانند یک فناوری یا یک ایده-متناسب با سن فعلی آنها است. در واقع ، هرچه چیزی طولانی تر در اطراف باشد ، شانس بیشتری وجود دارد که بیشتر زنده بماند و در بین الگوهای رفتاری ، رقابت برای بقا شدید است. در این جنگل متوسط طول عمر تقریباً چهار ماه است. در مقایسه با سایر الگوهای رفتاری ، Doge نوعی بزرگان محترم است. با زنده ماندن به مدت هشت سال - Doge Meme برای اولین بار در سال 2013 محبوب شد - قبلاً ثابت شده است که یکی از مقاوم ترین یادبودهای کل تاریخ اینترنت است. اثر Lindy نشان می دهد که به همین دلیل ، Dogecoin بیشتر از هر یادگار دیگر به آینده ادامه خواهد داد. درست همانطور که دلار ایالات متحده از قدرت هژمونیک آمریکا حمایت می شود ، Dogecoin توسط برخی از قدرتمندترین الگوهای یادآوری موجود - و جوامع پشت سر آنها پشتیبانی می شود. Dogecoin دارای یک فن فن واقعی است که استفاده از آن را از طریق شبکه های اجتماعی تبلیغ می کند. بخشی از آنچه Dogecoin را به یک رمزنگاری موفق تبدیل کرده است ، عدم تریبونیسم جامعه آن است.
علاوه بر این ، در حالی که از نظر فنی بسیار مشابه است (یعنی تقریباً همان موارد POW و استفاده) ، Litecoin جامعه کمتری دارد. علی رغم اینکه یک رمزنگاری قدیمی تر و با ثبات تر است ، Litecoin همان محبوبیت آنلاین را ندارد. کاربران Litecoin با صدای بلند نسبت به شبکه های اجتماعی بلند نیستند و به معنای سازماندهی خرید هماهنگ به منظور تأثیرگذاری بر ارزش ارز نیستند.
Litecoin و Dogecoin به دلیل شباهت آنها برای این مطالعه انتخاب شده اند. در واقع ، Litecoin یک اسپینوف اولیه بیت کوین (یا Altcoin) بود که از اکتبر 2011 شروع می شود (سابق گوگلر Worl ، 2018 را می دهد) ، و پروتکل Dogecoin بر اساس ارزهای رمزپایه موجود است: LuckyCoin و Litecoin (گیلبرت ، 2013). Dogecoin در 6 دسامبر 2013 (Noyes ، 2014) راه اندازی شد. در نگاه اول ، این ارزهای رمزنگاری متفاوت هستند و ممکن است قابل مقایسه نباشند.
همانطور که قبلاً توضیح داده شد ، اثر Lindy به Dogecoin - "Memecoin" اجازه می داد تا خود را از یک شوخی آزاد کند. بنابراین ، پس از مدت زمانی که Dogecoin نادیده گرفته شد (لاک ، 2021) ، توسط جامعه آن به عقب رانده شد و اخیراً دوباره مرسوم شد - هم در سطح فرزندخواندگی و هم در سطح توسعه فنی آن (بنیاد Dogecoin ((بنیاد Dogecoin ()2021 ، 2021) (کاهش هزینه های معاملات ، پل با ETH ، NFT های اول در شبکه آن ایجاد می شوند). اکنون ، ما می توانیم یک رویکرد غیر متمرکز واقعی را که از این رمزنگاری و جامعه آن ناشی می شود ، مشاهده کنیم. از طرف دیگر Litecoin دارای یک استتوسعه متمرکز تر - عمدتاً به دلیل سابقه آن - اما مانع از داشتن یکی از بزرگترین سرمایه ها نمی شود. بنابراین ، Litecoin یکی از اولین آلتکین ها بود ، و Dogecoin یکی از اولین یادداشت ها بود (اگر نه اول). هرگونه cryptocurrency در راه اندازی ، آینده آنها به جوامع مربوطه متکی است. ما تصمیم گرفتیم که به دلیل ذهنیت سوداگرانه محور آنها از Memecoins برای مقایسه استفاده نکنیم و تاکنون از شیوه زندگی Libertarian Cypherpunk حذف شده اند (هیوز ، 1993).
همانطور که به طور گسترده مورد مطالعه قرار گرفت و به خوبی مستند شد ، اقتصاد رمزنگاری و رفتار سنتی اقتصاد مالی حدود 20 تعصب شناختی مشهور دارد (Douziech ، 2021). در اینجا ، ما به این سؤال خواهیم پرداخت: "چه تاثیری در فعالیت آنلاین - از طریق توییتر در این مطالعه - در بازار cryptocurrency قرار دارد؟"سؤالاتی از این دست قبلاً مطرح شده و برای بیت کوین مورد مطالعه قرار گرفته است.
- شبکه های حلقوی موقتی به طور قابل توجهی بهتر از هر دو مدلهای مبتنی بر یادگیری و سایر یادگیری های عمیق در ادبیات عمل می کنند ، و نویسنده توییت متا اطلاعات ، حتی از خود توییت جدا شده است ، پیش بینی کننده بهتری نسبت به محتوای معنایی و آمار حجم توییت است (Akbiyikو همکاران ، 2021) ؛
- آزمون های آماری نشان می دهند که ساده ترین GARCH(1،1) بهترین واکنش را به افزودن یک سیگنال خارجی به منظور مدل سازی فرآیند نوسانات بر روی داده های خارج از نمونه دارد (Barjašić و Antulov-Fantulin، 2020).
به این ترتیب، ما در اینجا دو ارز دیجیتال اصلی (لایت کوین و دوج کوین) را بررسی خواهیم کرد.
• آیا قیمت ها و مبادلات ارزهای دیجیتال تحت تأثیر نوسان توییت های جامعه ارزهای دیجیتال است؟
• آیا می توان قیمت لایت کوین و دوج کوین را (بر اساس این فرض) پیش بینی کرد؟کدام مدل پیش بینی آماری بهترین عملکرد را دارد؟
• آیا دوج کوین یا هر Memecoin در واقع می تواند به ارز آینده تبدیل شود؟
مواد و روش ها
تجزیه و تحلیل ما به دو بخش تقسیم می شود:
- اولین مورد تحلیل همبستگی/علیت را پوشش می دهد
— دومی به پیش بینی قیمت احتمالی آن ارزهای دیجیتال بر اساس تحلیل علیت/همبستگی می پردازد.
تحلیل علیت و همبستگی
ما از دو روش برای ارزیابی وجود یا عدم وجود ارتباط بین X و Y استفاده کردیم. این دو روش همبستگی پیرسون کلاسیک و اطلاعات متقابل شانون نرمال شده بودند.
تنظیمات
ما از داده های تاریخی، از 01/01/2015 تا 03/11/2021، با استخراج ردیاب های اقتصادی مختلف به شرح زیر استفاده کردیم.
متغیرها
با هر روش، متغیرهای زیر را مطالعه کرده ایم: «تاریخ»، «بالا_100_درصد» 100 آدرس اول با کیف پول بزرگ در بلاک چین کریپتو مورد مطالعه (به عنوان مثال، «نهنگ»)، «متوسط_ارزش_تراکنش"، "کاپ_بازار"، "متوسط_ارزش_تراکنش،""active_addresses" در توییتر (یعنی مهمترین تأثیرگذاران)، و "tweets".
منابع اطلاعات
چارچوب داده از سه وب سایت (1، 2، 3) می آید، اما ما در اینجا از دو نسخه دیتافریم به دلیل کمبود ارقام برای روزهای خاص استفاده می کنیم. اولین فایل، فایل اصلی است که حاوی مقادیر "تهی" است. اما، برای کار با الگوریتم ما، آنها (در فایل دوم) با مقدار میانگین آخرین مقدار موجود و مقدار بعدی پر شده اند. این به ما این امکان را می دهد که با فایل های خود کار کنیم بدون اینکه تعصب جدیدی در همبستگی های خود وارد کنیم.
روش آماری
بدیهی است که همبستگی علیت نیست. اما فقدان همبستگی دلالت بر عدم وجود علیت دارد. بنابراین، همبستگی (که ممکن است منفی یا مثبت باشد) یکی از اجزای کلیدی فرآیند علمی است، زیرا مجموعه ای از متغیرها را نشان می دهد که ممکن است با یکدیگر تعامل داشته باشند و در نتیجه نیاز به مطالعه بیشتر دارد. در مقابل، این روش همچنین برای رد زودهنگام فرضیه های غیر موجه در رابطه با چنین تعامل بین متغیرها به حساب می آید.
اولین روشی که ما استفاده کردیم بر اساس ماتریس همبستگی پیرسون (Caut et al. ، 2021) است و محاسبات با استفاده از کتابخانه Python Numpy انجام شد. سپس ، ما نتایج را با دو فرمول پیرسون برای سریال های گسسته و سری مداوم کنترل کردیم. به طور خاص ، ما از عملکرد زیر استفاده کردیم:
numpy. corrcoef (df [cols]. oreals. t).
- DF Dataframe از داده ها است
- Cols لیست ستون های مورد استفاده برای ماتریس است
اول ، بگذارید در مورد همبستگی پیرسون صحبت کنیم: این یک انتقاد متداول است که ممکن است فرد بین یک سری از متغیرهای کمی و دیگری یکی از متغیرهای کیفی ارتباط خطی برقرار نکند. با این حال ، این به ما کمک می کند تا آن همبستگی ها را همانطور که به آنها نگاه می کنیم ، شناسایی کنیم (لو ، 1949 ؛ تیت ، 1954 ؛ کورنبروت ، 2005). همبستگی پیرسون رابطه خطی بین دو متغیر مداوم را ارزیابی می کند. گفته می شود که وقتی اصلاح یکی از متغیرها با اصلاح متناسب متغیر دیگر همراه است ، رابطه خطی است.
همبستگی Spearman رابطه یکنواخت بین دو متغیر مداوم یا منظم را ارزیابی می کند. در یک رابطه یکنواخت ، متغیرها تمایل دارند که با هم تغییر کنند اما لزوماً با سرعت ثابت نیستند. این ضریب همبستگی بر اساس مقادیر رتبه بندی شده هر متغیر به جای داده های خام است. بنابراین ، با توجه به متغیرهای مداوم که ما مطالعه خواهیم کرد ، همبستگی پیرسون برای مطالعه تأثیر فوری توییت ها بر پارامترهای اقتصادی Dogecoin و Litecoin مناسب تر به نظر می رسد.
روش دوم مبتنی بر آنتروپی اطلاعات متقابل است (Pébaÿ ، 2021 ؛ Pébaÿ و همکاران ، 2021). این به ما امکان می دهد از فرض محدودیت یکنواختی مورد نیاز همبستگی خطی عاری باشیم. این مقدار اطلاعات را اندازه گیری می کند (به معنای تعریف شده توسط کلود شانون در سال 1948 (شانون ، 1948)) که دو توزیع به اشتراک می گذارند. به عبارت دیگر ، این ارتباط ("خوشه بندی") بین دو متغیر را اندازه گیری می کند: توجه به این نکته مهم است که رویکرد وی همبستگی خطی نیست بلکه آنتروپی اطلاعات کلاسیک است. در واقع ، ما یک مقدار بدون بعد را محاسبه کردیم ، که عموماً در واحدهای بیت بیان شده است (تامپسون و پبی ، 2009) ، که ممکن است با توجه به دانش دیگری به عنوان کاهش عدم اطمینان در مورد یک متغیر تصادفی تصور شود. به عنوان مثال ، اطلاعات متقابل بالا به معنای کاهش زیاد در عدم اطمینان در یک متغیر ، با توجه به دیگری است ، در حالی که اطلاعات متقابل کم نشانگر کاهش اندک در این عدم اطمینان است. سرانجام ، اطلاعات متقابل صفر بین دو متغیر تصادفی هیچ ارتباطی بین این دو توزیع ندارد (McDaid و همکاران ، 2011). علاوه بر این ، قضیه کدگذاری منبع شانون مرزهای سختی را در مورد آنچه در مورد یک سری داده ها شناخته می شود تعیین می کند و ممکن است فشرده شود - که به نوبه خود ، توضیح می دهد که چگونه و تا چه اندازه یک متغیر ممکن است یک نماینده دیگر بدون از دست دادن داده باشد. آنتروپی اطلاعات شانون نشان داده شده است که هنگام ارزیابی با روش تجزیه بلوک ، برای ارزیابی پیچیدگی الگوریتمی کارآمد است (Zenil et al. ، 2016 ؛ Zenil ، 2020). علاوه بر این ، به گفته N. N. Taleb ، معیارهای آنتروپی عملاً همه پارادوکس های همبستگی را در زمینه علوم اجتماعی (یا به عبارت بهتر ، شبه پارادوکس) حل می کنند (Taleb ، 2019). نمونه مهم دیگر از اهمیت این تکنیک ، انتخاب موجک مادر است ، جایی که حساسیت برتر را برای تعیین کمیت در ساختار سیگنال نسبت به خطای میانگین مربع و ضریب همبستگی نشان داد (Wijaya et al. ، 2017).
روش های دیگر را می توان نقل کرد: مدل های اقتصادسنجی کلاسیک ، به عنوان مدل ناهمگونی مشروط بر اساسنامه مبتنی بر موجک (محمد و همکاران ، 2020 ؛ گوستی لیما و آساف نتو ، 2022) ، یا استنباط علی در مجموعه داده های سری زمانی (و بنابراین بیش از راه حلفرآیندها) (پالاچی ، 2019 ؛ شیمونی و همکاران ، 2019).
بنابراین ، به منظور محاسبه نتایج قابل تکرار ، از بسته "Muinther" R موجود در GitHub استفاده می کنیم ، که از این دو روش آماری استفاده می کند (Lansiaux et al. ، 2021).
تعصب
اولین تعصب مهم اندازه جامعه است. در واقع ، این می تواند بر روش پیرسون تأثیر بگذارد ، بیشتر مستعد این موضوعات باشد. با این حال ، یک جامعه بزرگتر قادر به کاهش تغییرات شدید متغیرهای مورد مطالعه (تعداد توییت ها) خواهد بود. بنابراین ، برای دو روش ، ما قادر به مقایسه داده های خام از نمونه ها نخواهیم بود بلکه فقط ضرایب (از نظریه اطلاعات پیرسون یا نرمال شده) بین این دو ارز رمزنگاری شده است.
تعصب دوم روش پیرسون به خودی خود است. در واقع ، با تعریف خود ، همبستگی پیرسون رابطه خطی بین دو متغیر مداوم را ارزیابی می کند. گفته می شود که وقتی اصلاح یکی از متغیرها با اصلاح متناسب متغیر دیگر همراه است ، رابطه خطی است. با این حال ، اگر کسی در یک رابطه یکنواخت حرکت کند ، متغیرها تمایل دارند که با هم تغییر کنند اما لزوماً با سرعت ثابت نیستند (د وین و همکاران ، 2016). در این حالت ، همبستگی Spearman بهتر خواهد بود.
مدل پیش بینی قیمت
تنظیمات
ما از داده های تاریخی، از 01/01/2015 تا 03/11/2021، با استخراج ردیاب های اقتصادی مختلف به شرح زیر استفاده کردیم.
متغیرها
از سه متغیر در درجه اول استفاده شد:
- "توییت" (یک متغیر مداوم که تعداد توییت ها را در روز با ذکر علاقه به cryptocurrency توصیف می کند) ،
- "قیمت" (یک متغیر مداوم که قیمت بسته شدن تعدیل شده از رمزنگاری علاقه مند را توصیف می کند).
اگر یکی از این مقادیر از دست رفته باشد ، داده ها سانسور می شوند. به این ترتیب ، ما برای هر متغیر 2،482 داده به دست آوردیم.
منابع اطلاعات
توییت ها از API توییتر جمع آوری و استخراج شدند و قیمت ها در امور مالی یاهو (3) استخراج شد.
روش آماری
همبستگی قیمت/علیت با شماره توییت
از همین روش برای کشف رابطه همبستگی و علیت بین قیمت Dogecoin/Litecoin و شماره توییت استفاده شد. به عبارت دیگر ، ما ابتدا از روش همبستگی پیرسون و سپس آنتروپی اطلاعات متقابل شانون برای ارزیابی آن استفاده کردیم (همه از بسته "Muinther" R استفاده کردیم.
کاربرد
به دنبال تجزیه و تحلیل همبستگی/علیت ، ما قادر خواهیم بود تا دو کارکرد را تعیین کنیم تا رابطه ای بین قیمت ارز و شماره توییت در مقطعی "t" برقرار کنیم.
مدل ها
تست دیکی - پررنگ
از آنجایی که داده های Litecoin و Dogecoin ما مجموعه داده های سری زمانی هستند، مهم است که بررسی کنیم که آیا داده ها ممکن است به نوعی ثابت باشند یا خیر. برای بررسی این موضوع، یک آزمون ADF (مخفف دیکی-فولر تقویت شده) را در نظر گرفتیم. این ریشه های واحد دلیلی برای ایجاد نتایج غیرقابل پیش بینی در تحلیل داده های سری زمانی هستند. بنابراین، ADF یک آزمون معنی داری است، بنابراین یک فرضیه صفر و جایگزین با آن وارد می شود، آمار آزمون محاسبه می شود و p-value گزارش می شود. بر اساس p-values، ثابت بودن داده ها تعیین می شود. اساسا، ADF روند داده ها را تعیین می کند و تعیین می کند که سری زمانی با یک روند چقدر قوی یا ضعیف تعریف می شود. با این حال، ما از سه مدل رگرسیون خطی برای ارزیابی آن استفاده می کنیم.
1) نوع اول (نوع 1) یک مدل خطی بدون رانش و روند خطی نسبت به زمان است:
dx ( t ) = ρ∗x ( t − 1 ) + β ( 1 ) ∗dx ( t − 1 ) + .+ β ( nlag - 1 ) ∗dx ( t - nlag + 1 ) + e ( t ) ,
که در آن d یک عملگر اختلاف مرتبه اول است، یعنی dx(t) = x(t) - x (t-1)، و e(t) یک عبارت خطا است.
2) نوع دوم (نوع 2) یک مدل خطی با رانش اما بدون روند خطی است:
dx (t) = μ + ρ ∗x (t - 1 ) + ( 1 ) ∗dx ( t - 1 ) + … + ( nlag - 1 ) ∗dx ( t - nlag + 1 ) + e ( t )
3) نوع سوم (نوع 3) یک مدل خطی با دو روند رانش و خطی است:
dx ( t ) = μ + β ∗t + ρ ∗x [ t - 1 ] + β ( 1 ) ∗dx ( t - 1 ) + … + ( nlag - 1 ) ∗dx ( t - nlag + 1 ) + e( تی ) .
داده های ثابت به این معنی است که ویژگی های آماری داده ها به زمان بستگی ندارد. اگر داده های داده شده غیر ثابت هستند، باید با اعمال یک گزارش طبیعی، آن را به ثابت بودن تغییر دهیم.
آریما
مدلی که ما برای استفاده انتخاب می کنیم ARIMA (مخفف AutoRegressive Integrated Moving Average) است. این بخشی از مدل های رگرسیون خطی است که عمدتاً برای پیش بینی مقادیر آینده بر اساس رفتار گذشته هدف استفاده می شود. می گویند تاریخ تکرار نمی شود، اما مطمئناً ریتم خاص خود را داشته و دارد. زیبایی مدل های ARIMA این است که این مدل ها از مقادیر برون زای تحمیل شده به آن ها استفاده نمی کنند، بلکه کاملاً به مقادیر هدف گذشته برای پیش بینی وابسته هستند. ARIMA را می توان به صورت AR، I و MA شکست. همانطور که قبلا ذکر شد، AR مخفف Auto-Regressive است و بر روی ایده پسرفت هدف در متغیر گذشته خود کار می کند، که چیزی جز عقب افتادن در خود نیست. معادله1 یک مقدار را نشان می دهد که Y تابع خطی n مقدار گذشته آن است. این n مقدار را می توان انتخاب کرد و مقادیر بتا هستند که در برازش مدل استفاده می شوند. این معادله با ایجاد تغییرات زیر مانند معادله به پیش بینی مقادیر آینده کمک می کند. 2.
بخش یکپارچه ARIMA با ثابت کردن داده ها سروکار دارد. در اینجا، تفاوت بر روی داده ها اعمال می شود، همانطور که در معادله نشان داده شده است. 3. نشان می دهد که مقادیر آینده Y تابع خطی تغییرات گذشته آن هستند. دلیل تفاوت این است که داده های سری زمانی پایدار نیستند و مقادیر Y باید دارای واریانس میانگین ثابت باشند.
میانگین متحرک همه در معادله خلاصه می شود. 4، تا حدودی شبیه به معادله AN با تاخیر. E نشان می دهد که خطا در داده ها چیزی نیست جز مشتقات باقی مانده بین مدل و مقدار هدف.
این نماد استاندارد برای نشان دادن مدل های ARIMA است. این پارامترها را می توان با مقادیر صحیح جایگزین کرد تا نوع مدل مورد استفاده را مشخص کند. پارامتر «p» به ترتیب تأخیر AR گفته می شود، یعنی تعداد تأخیرهایی در Y که در مدل گنجانده می شود، «d» ترتیب تفاضل مورد نیاز برای ثابت کردن داده ها و «q» ارجاع می شود. به ترتیب MA، یعنی تعداد خطاهای پیش بینی تاخیر.
معیارها
چندین مدل مختلف (به عنوان مثال ، بر اساس سفارشاتی مانند مدل های AR و ARMA با ترتیب خاص یا نظم متفاوت) برای سری زمانی ساختمان وجود دارد. هرچه مقدار به دست آمده با استفاده از این معیارها پایین تر باشد ، الگویی برای داده های سری زمانی ما مناسب تر خواهد بود. پارامترهای مورد استفاده در این معیارها عبارتند از: احتمال ابتلا به احتمال (L) ، نشان می دهد که مدل در متناسب بودن داده ها چقدر قوی است. به طور کلی ، در نظر گرفته می شود که هرچه مدل پیچیده تر باشد ، با داده ها بهتر می شود. اگرچه در اتصالات صحیح است ، اما همچنین از مفهوم بیش از حد استفاده می کند (یعنی مدل متناسب با داده های آموزش بهتر است اما توانایی خود را در تعمیم داده های آزمون از دست می دهد). برای جلوگیری از آن ، تعداد پیش بینی کننده های K (یعنی تعداد تاخیر (مقدار ثابت زمان عبور)) به علاوه ثابت درج شده است. پارامتر دیگری که در اینجا مورد توجه قرار می گیرد ، تعداد نمونه ها یا مشاهدات مورد استفاده برای تخمین است.
در زیر معیارهای مورد استفاده در این آزمایش برای انتخاب بهترین مدل ذکر شده است.
• معیار اطلاعات Akaike (AIC) - از AIC برای تعیین ترتیب یک مدل ARIMA استفاده می شود و همچنین می تواند برای انتخاب پیش بینی کننده های مدل رگرسیون استفاده شود. AIC را می توان با استفاده از فرمول ذکر شده در زیر محاسبه کرد.
اگر مقادیر t کم باشد ، AIC ممکن است پیش بینی های زیادی را پیش بینی کند ، بنابراین برای جلوگیری از این تعصب ، نسخه اصلاح شده AIC ، یعنی AICC ، در نظر گرفته می شود.
در جایی که L مقدار احتمال وجود دارد ، P ترتیب مدل AR است ، q ترتیب مدل MA است ، k تعداد پیش بینی کننده ها است و T تعداد مشاهداتی است که برای تخمین همانطور که در بالا ذکر شد استفاده می شود. برای به دست آوردن بهترین مدل ، باید مدل را با مقدار AIC پایین در نظر بگیریم. این بدان معناست که مقدار k باید کم باشد ، و مقدار L باید در حداکثر خود باشد ، نشان می دهد که مدل ساده خواهد بود زیرا K کم است و داده ها را به خوبی با حداکثر L متناسب می کند.
• معیار اطلاعات بیزی (BIC) - BIC ، همچنین به عنوان معیار اطلاعات شوارتز شناخته می شود ، برای انتخاب مدل بر اساس نمره به دست آمده استفاده می شود.
در اینجا همچنین ، حداقل مقدار باید مورد توجه قرار گیرد. BIC با یک مقدار کوچک نشان می دهد که مدل ساده است ، با شماره K نسبتاً کم ، که به بهترین وجه مدل است و در چند مشاهده آموزش داده می شود. علاوه بر این ، مطالعات دیگر نشان داده اند که مدل ARIMA پتانسیل قوی برای پیش بینی کوتاه مدت دارد و می تواند با تکنیک های موجود در پیش بینی قیمت سهام رقابت کند (ماهان و همکاران ، 2015).
IMV-LSTM
سرانجام ، ما از دقت یادگیری عمیق SOA خود استفاده و ارزیابی خواهیم کرد-به ویژه شبکه های عصبی حافظه کوتاه مدت چند متغیره قابل تفسیر (Guo et al. ، 2019). ما از پیاده سازی موجود در Pytorch 4 استفاده می کنیم. در واقع ، طبق یک مطالعه قبلی (Barić و همکاران ، 2021) ، به نظر می رسد تنها الگویی با نمره عملکرد رضایت بخش و هم تفسیر صحیح است ، و هم همبستگی ها و هم همبستگی های بین سری های زمانی را ضبط می کند. جالب توجه است ، ضمن ارزیابی IMV-LSTM در داده های شبیه سازی شده از مدلهای آماری و مکانیکی ، صحت تفسیر با مجموعه داده های پیچیده تر افزایش می یابد.
مدل های دیگر اغلب در این دامنه مورد استفاده قرار می گیرند ، از جمله برنامه های پیشرفته مدل به پیش بینی احتمالی مانند catboostls (یا جنگل های رگرسیون کمی) (دانیل ، 2019) و فرآیندهای گاوسی در یک رگرسیون خطی پویا ، به عنوان جایگزینی برای این امر جایگزینی برایKalman Filter 5.
در دسترس بودن داده ها
تمام داده های تولید شده یا تجزیه و تحلیل در طی این مطالعه در این مقاله منتشر شده (و مخزن آن 6) گنجانده شده است.
نتایج
همبستگی و تجزیه و تحلیل علیت
تجزیه و تحلیل همبستگی پیرسون
لیتر
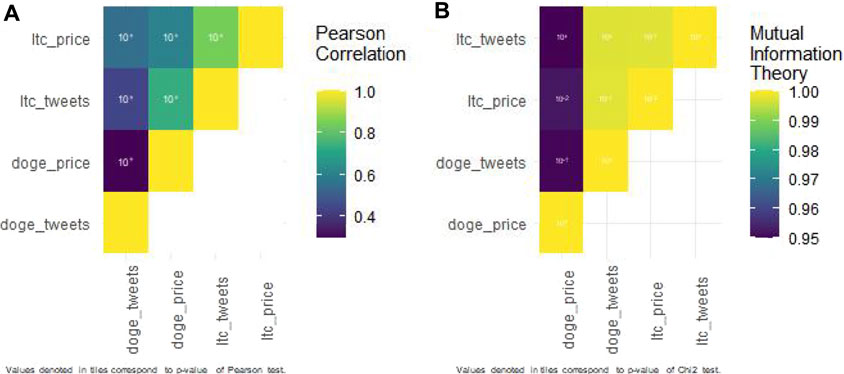
تمام همبستگی های پیرسون مورد مطالعه با Litecoin (پرونده تکمیلی S1 و شکل 1a) با یک p-Value تحت 0. 001 معنی دار بود ، به جز همبستگی بین کلاه بازار Litecoin و میانگین ارزش معامله Litecoin ( p-value = 5. 938*10^-3).
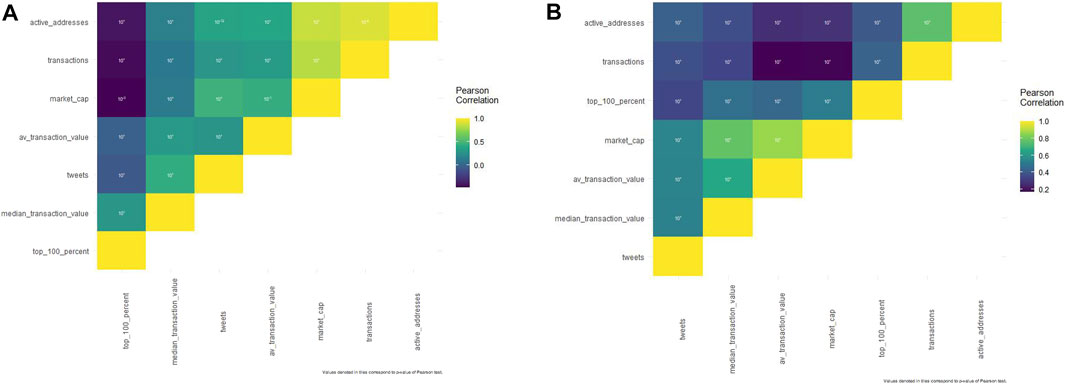
شکل 1 .(آ) . ماتریس همبستگی پیرسون در مورد Dogecoin.(ب). ماتریس همبستگی پیرسون در مورد Dogecoin.
توییت ها تأثیر منفی کمی در رفتار نهنگ Litecoin دارند (ضریب پیرسون = -0. 057). آنها با ارزش معاملات متوسط Litecoin (0. 449) ، میانگین ارزش معاملات Litecoin (0. 2944) ، کلاه بازار Litecoin (0. 469) ، معاملات Litecoin (0. 296) و آدرس های فعال Litecoin (0. 376) همبستگی مثبت دارند.
نتایج دیگر ممکن است تعجب آور به نظر برسد: نهنگ های Litecoin با آدرس های فعال Litecoin (39/0 -) ، معاملات (439. 0. 439)) ، کلاه بازار (466 -) و میانگین ارزش معاملات Litecoin (0. 010 -) اما با ارزش معاملات متوسط Litecoin ارتباط منفی دارند (0. 308).
سگکین
همه همبستگی های پیرسون برای Dogecoin (پرونده تکمیلی S2 و شکل 1b) مورد مطالعه قرار گرفتند ، با P-Value زیر 0. 001.
توییت ها با کلیه متغیرهای اقتصادی با ارزش معاملات Dogecoin متوسط (0. 534) ، میانگین ارزش معاملات Dogecoin (0. 543) ، کلاه بازار Dogecoin (0. 549) ، نهنگ های Dogecoin (0. 343) ، معاملات Dogecoin (0. 376) و آدرسهای فعال Dogecoin (0. 430 فعال (0. 430 فعال) همبستگی مثبت دارند.).
نهنگ های Dogecoin با آدرس های فعال Dogecoin (0. 405) ، معاملات Dogecoin (0. 436) ، کلاه بازار Dogecoin (0. 520) ، میانگین ارزش معاملات Dogecoin (0. 452) و ارزش معامله Dogecoin (0. 476) ارتباط مثبت دارند.
تجزیه و تحلیل تئوری اطلاعات متقابل.
لیتر
تجزیه و تحلیل "انجمن"
توییت های جامعه به شدت (با ضریب اطلاعات متقابل عادی حداقل 0. 9) مرتبط هستند (شکل 2A و جدول تکمیلی S1) با تمام متغیرهای Litecoin اما با P-Values نوسان.
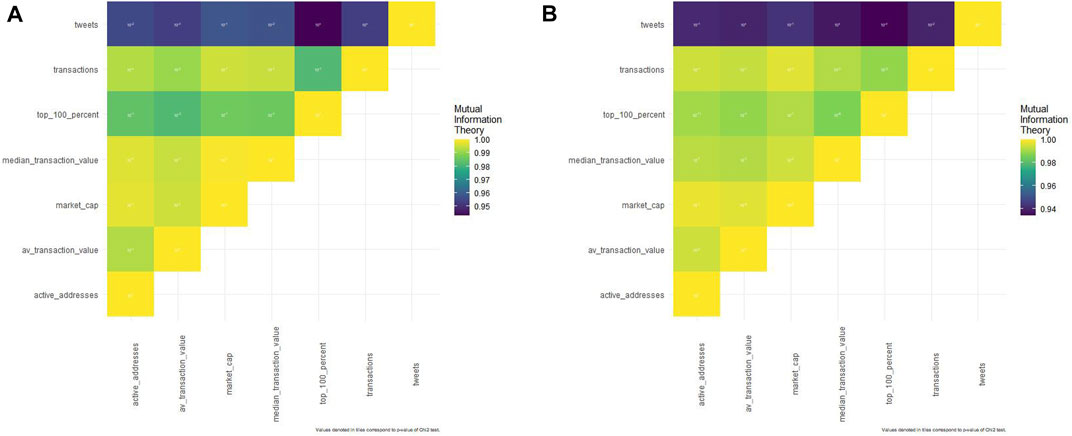
شکل 2 .(آ) . ماتریس تئوری اطلاعات متقابل در مورد Litecoin.(ب). ماتریس تئوری اطلاعات متقابل در مورد سگکوئین.
در واقع ، فقط تعداد معدودی از ارتباطات P-Values قابل توجه هستند: مقدار متوسط معامله Litecoin با توییت ( P-Value = 0. 0005) ، مقدار متوسط معامله Litecoin با نهنگ ها (0. 003) ، آدرس های فعال Litecoin با توییت (0. 03) ، معاملات Litecoin با توییت (0) ، معاملات Litecoin با آدرس های فعال Litecoin (0. 0005) و معاملات Litecoin با مقدار متوسط معامله Litecoin (0. 016).
تحلیل "علیت"
ما فقط علیت ارتباط معنی داری (که قبلاً توضیح داده شده بود) را کشف و تأکید خواهیم کرد.
در مورد ارتباط توییت با ردیاب های اقتصادی ، شماره توییت توسط معاملات Litecoin تحت تأثیر قرار گرفت [آنتروپی اطلاعات مشروط توییت های داده شده Litecoin (0. 637) بالاتر از آنتروپی اطلاعات شرطی با داده های Litecoin با توجه به توییت ها (0. 070) به عنوان جدول مکمل S1] و توییت است. تعداد تحت تأثیر میانگین معاملات Litecoin نیز تحت تأثیر قرار گرفت [آنتروپی اطلاعات شرطی توییت با توجه به میانگین ارزش معامله Litecoin (0. 637) بالاتر از آنتروپی اطلاعات مشروط از مقدار متوسط معامله Litecoin با توجه به توییت ها (0. 071)] است.
هنگام نگاه به انجمن های دیگر ، می بینیم که آدرس های فعال Litecoin تحت تأثیر معاملات Litecoin قرار می گیرند [آنتروپی اطلاعات مشروط آدرسهای فعال Litecoin با توجه به معاملات Litecoin (0. 071) بالاتر از آنتروپی اطلاعات مشروط با داده های Litecoin (0. 037)]]و معاملات Litecoin تحت تأثیر ارزش متوسط معامله Litecoin قرار می گیرد [آنتروپی اطلاعات مشروط معاملات Litecoin با توجه به میانگین ارزش معامله Litecoin (0. 071) بالاتر از آنتروپی اطلاعات مشروط از ارزش متوسط معامله Litecoin با توجه به معاملات Litecoin (0. 070)] است.
سگکین
تجزیه و تحلیل "انجمن"
توییت های جامعه به شدت (با ضریب اطلاعات متقابل عادی حداقل 0. 9) مرتبط هستند (شکل 2B و جدول تکمیلی S2) به کلیه متغیرهای سگکین اما با P-Values نوسان.
همچنین مقادیر قابل توجهی p (زیر 0. 05) وجود دارد ، اما فقط با انجمن های خاص: معاملات Dogecoin با ارزش معاملات Dogecoin متوسط (0. 03) ، معاملات Dogecoin با نهنگ های Dogecoin (0. 003) ، میانگین ارزش معاملات Dogecoin با کلاه بازار Dogecoin (0. 011) ، ،میانگین ارزش معاملات Dogecoin با توییت (0) ، نهنگ های Dogecoin با آدرس های فعال Dogecoin (3. 41 * 10^-11) و نهنگ های Dogecoin با توییت (3. 22 * 10^-4).
تحلیل "علیت"
ما فقط علیت ارتباط معنی داری (که قبلاً توضیح داده شده بود) را کشف و تأکید خواهیم کرد.
هنگامی که به انجمن های توییت و ردیاب های اقتصادی Dogecoin نگاه می کنیم ، متوجه می شویم که میانگین ارزش معاملات Dogecoin توسط توییت ها تحت تأثیر قرار می گیرد [آنتروپی اطلاعات مشروط از ارزش معاملات Dogecoin به طور متوسط با توجه به توییت ها (0. 861) بالاتر از آنتروپی اطلاعات مشروط با توجه به میانگین معاملات Dogecoin است. مقدار (0. 048)] و توییت ها توسط نهنگ های Dogecoin تحت تأثیر قرار می گیرند [آنتروپی اطلاعات مشروط توییت هایی که نهنگ های Dogecoin داده می شوند (0. 861) بالاتر از آنتروپی اطلاعات مشروط از نهنگ های Dogecoin با توییت (0. 124)] است.
در مورد سایر انجمن ها ، عمدتا به نهنگ ها نگاه می کنند. آدرسهای فعال Dogecoin توسط نهنگ های Dogecoin تحت تأثیر قرار می گیرند [آنتروپی اطلاعات مشروط آدرسهای فعال Dogecoin با توجه به نهنگ های Dogecoin (0. 120) بالاتر از آنتروپی اطلاعات مشروط از نهنگ های Dogecoin با داده های فعال Dogecoin (0. 029)] است. نهنگ های Dogecoin تحت تأثیر معاملات Dogecoin قرار می گیرند [آنتروپی اطلاعات مشروط از نهنگ های Dogecoin با توجه به معاملات Dogecoin (0. 124) بالاتر از آنتروپی اطلاعات شرطی معاملات Dogecoin با توجه به نهنگ های Dogecoin (0. 049)] است.
در مورد سایر انجمن ها ، معاملات Dogecoin بر ارزش معاملات Dogecoin تأثیر می گذارد [آنتروپی اطلاعات مشروط ارزش معاملات Dogecoin با توجه به معاملات Dogecoin (0. 078) بالاتر از آنتروپی اطلاعات مشروط با معاملات Dogecoin با توجه به ارزش معاملات Dogecoin متوسط (0. 049)] است. و میانگین ارزش معاملات Dogecoin توسط کلاه بازار Dogecoin تحت تأثیر قرار می گیرد [آنتروپی اطلاعات مشروط ارزش متوسط معامله Dogecoin با توجه به کلاه بازار Dogecoin (0. 047) بالاتر از آنتروپی اطلاعات مشروط درپوش بازار Dogecoin با توجه به میانگین ارزش معاملات Dogecoin (0. 001)] است.
مدل پیش بینی قیمت
با توجه به داده های تاریخی Litecoin/Dogecoin ، ما ابتدا قیمت و تحول حجم را طی این سالها تجزیه و تحلیل کردیم. از آنجا که داده های قیمت یک مجموعه داده سری زمانی است ، لازم است این مکان را برای ساخت مدل بررسی کنید.
تست ثابت
ما از تست ADF برای تعیین خاصیت متغیر سری زمانی خود استفاده کردیم. برای انجام این کار ، با توجه به فرضیه های تهی و جایگزین به عنوان بازنمایی داده های آزمون با استفاده از ریشه واحد یا غیر ثابت انجام می شود.
آمار ADF و P-Value از متغیرهای سری زمانی محاسبه شد. نتایج (جدول 1) به شرح زیر بود:
-داده های غیر ثابت Dogecoin هیچ روندی در هر دو مدل (بدون مقدار p قابل توجه) نشان نمی دهد (شکل 3a.).
-داده های غیر ثابت Litecoin هیچ روندی در هر دو مدل نشان نمی دهد اما با ارزش P قابل توجهی فقط در مورد سوم (شکل 4a.).
- داده های ثابت Dogecoin عدم وجود روند قابل توجهی در مدل اول ، عدم وجود روند غیر مهم در مدل سوم و حضور روند ناچیز در مدل دوم را نشان می دهد (شکل 3B).
- داده های ثابت Litecoin حضور روند ناچیز در مدل اول و غیبت روند ناچیز در مدل دوم و سوم را نشان می دهد (شکل 4B).

میز 1 . نتایج آزمون دیک ی-فولر تقویت شده برای سه نوع مدل رگرسیون خطی.
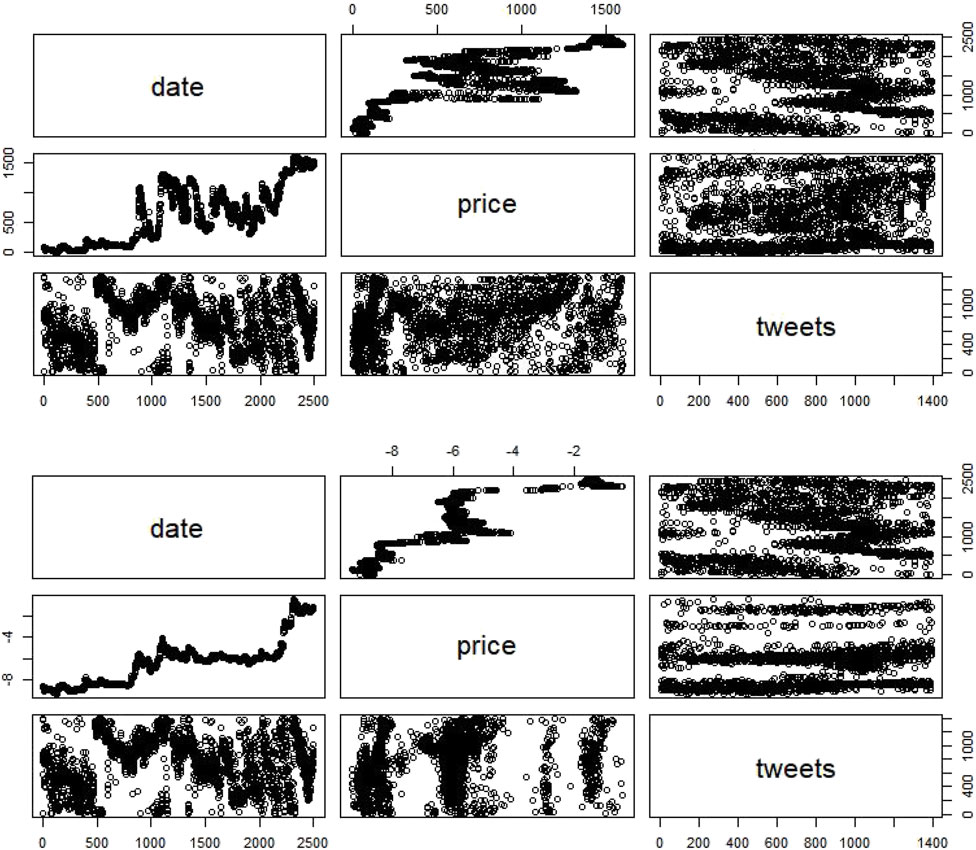
شکل 3. داده های غیر ثابت و ثابت Dogecoin.
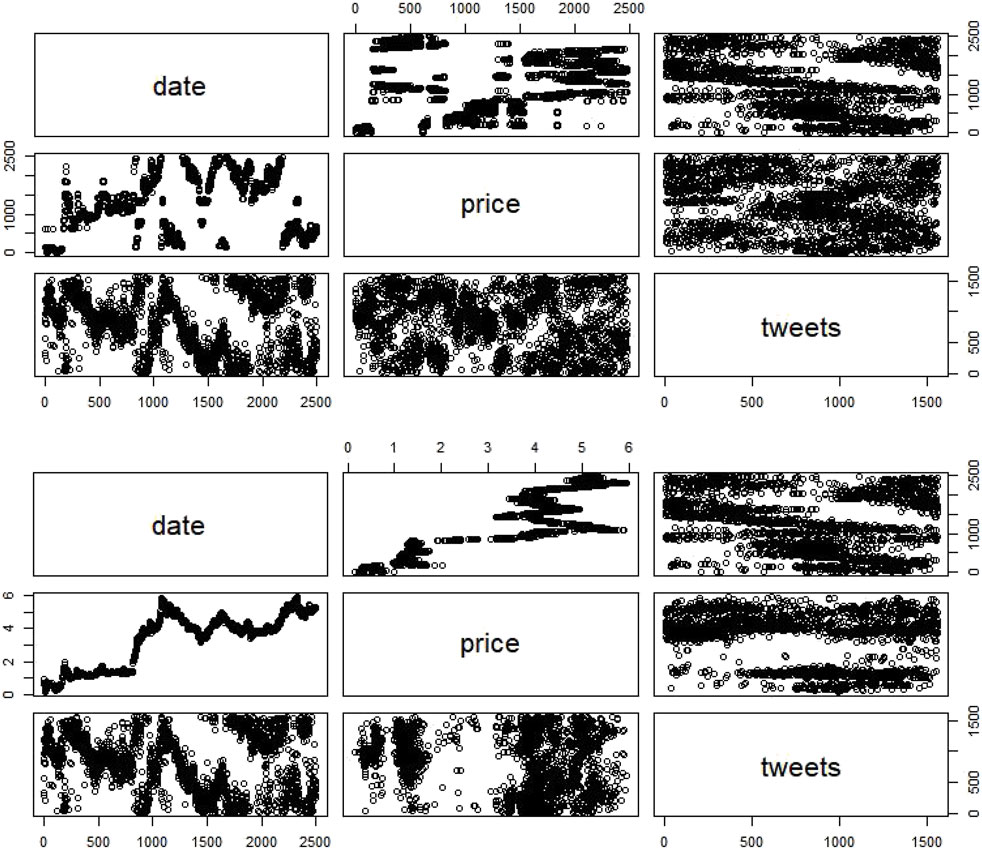
شکل 4داده های غیر ثابت و ثابت Litecoin.
برای اینکه آن را ثابت کنیم و روند را حذف کنیم ، ما به سادگی یک لگاریتم طبیعی را بر روی مقادیر قیمت Litecoin و Dogecoin اعمال کردیم. مقادیر سری زمانی قبل و بعد از حذف روند را می توان در جدول یافت. به این ترتیب ، مدل سوم (یک مدل خطی با هر دو روند رانش و خطی) بهترین مورد برای مطالعه روند ممکن در این داده ها بود. شکل 5 داده های غیر ثابت (بدون و با تغییر مقیاس مربع) و قیمت داده های ثابت داده V/S را نشان می دهد که با مدل سوم مورد مطالعه قرار گرفته است.

شکل 5تجزیه و تحلیل روند قیمت.
همبستگی قیمت/علیت با تعداد توییت ها
درباره همبستگی پیرسون بین قیمت ارز و توییت (شکل 6A و جدول 2) ، قیمت Dogecoin با توییت های جامعه Dogecoin ضعیف است (R = 0. 29) ، در حالی که موارد Litecoin با توییت های انجمن Litecoin ارتباط برقرار می کنند (R = 0. 86). این نتایج قابل توجه است زیرا الگوریتم R ما یک P-Value 0 گرد را محاسبه کرده است.
شکل 6. همبستگی و خطاهای گرما در مورد توییت ها و قیمت رمزنگاری.
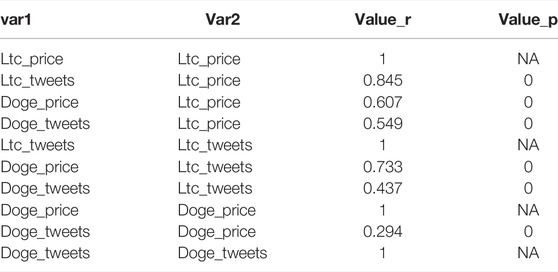
جدول 2ضرایب همبستگی پیرسون و P-Value برای توییت و رابطه قیمت cryptocurrency.
درباره انجمن مورد بررسی با آنتروپی اطلاعات متقابل شانون (شکل 6B و جدول 3) ، هر دو پیوند Dogecoin و Litecoin بین شماره صدای جیر جیر جامعه و قیمت آنها قوی است (به ترتیب 950 و 0. 998). با این حال ، مورد اول به اندازه مورد دوم ( p-value = 0. 18) معنی دار نیست ( p-value = 0. 15).
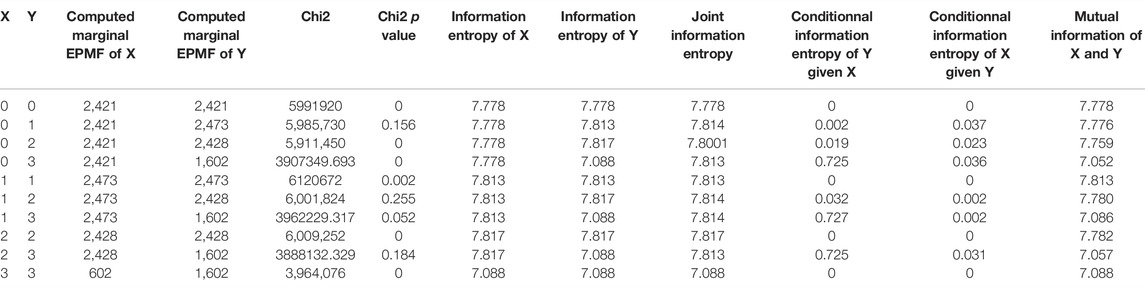
جدول 3. خروجی های آنتروپی برای توییت ها و روابط قیمت cryptocurrency.
درباره علیت کاوش شده با آنتروپی اطلاعات متقابل شانون (جدول 3):
- شماره توییت Dogecoin بر قیمت Dogecoin تأثیر گذاشت. در حقیقت ، آنتروپی اطلاعات مشروط از قیمت Dogecoin با توجه به شماره توییت Dogecoin (0. 724) بالاتر از آنتروپی اطلاعات مشروط با شماره توییت Dogecoin با توجه به قیمت Dogecoin (0. 031) است.
- شماره توییت Litecoin با قیمت Litecoin تحت تأثیر قرار می گیرد. در حقیقت ، آنتروپی اطلاعات مشروط شماره توییت Litecoin با توجه به قیمت Litecoin (0. 037) بالاتر از آنتروپی اطلاعات مشروط با توجه به شماره توییت Litecoin است.(0. 002).
کاربرد
با توجه به تجزیه و تحلیل همبستگی/علیت قبلی ، می توانیم رابطه بین قیمت ارز P و شماره توییت جامعه C را در یک زمان t (EQ 8 و 9) توصیف کنیم.
سپس ، به منظور تجزیه و تحلیل این کیفیت رگرسیون ، برای هر cryptocurrency (شکل 7A ، شکل 8A ، جدول 4.) ، ما آزمایش های ANOVA را انجام داده ایم ، داده های باقیمانده در مقابل داده های مناسب ، مکان در مقیاس باقیمانده محاسبه شده ، با مقایسه با مقایسه با مقایسه نرمال انجام می شود. مقدار جمعیت با قانون عادی ، و داده های باقیمانده در مقابل داده های اهرم مقایسه شده است.
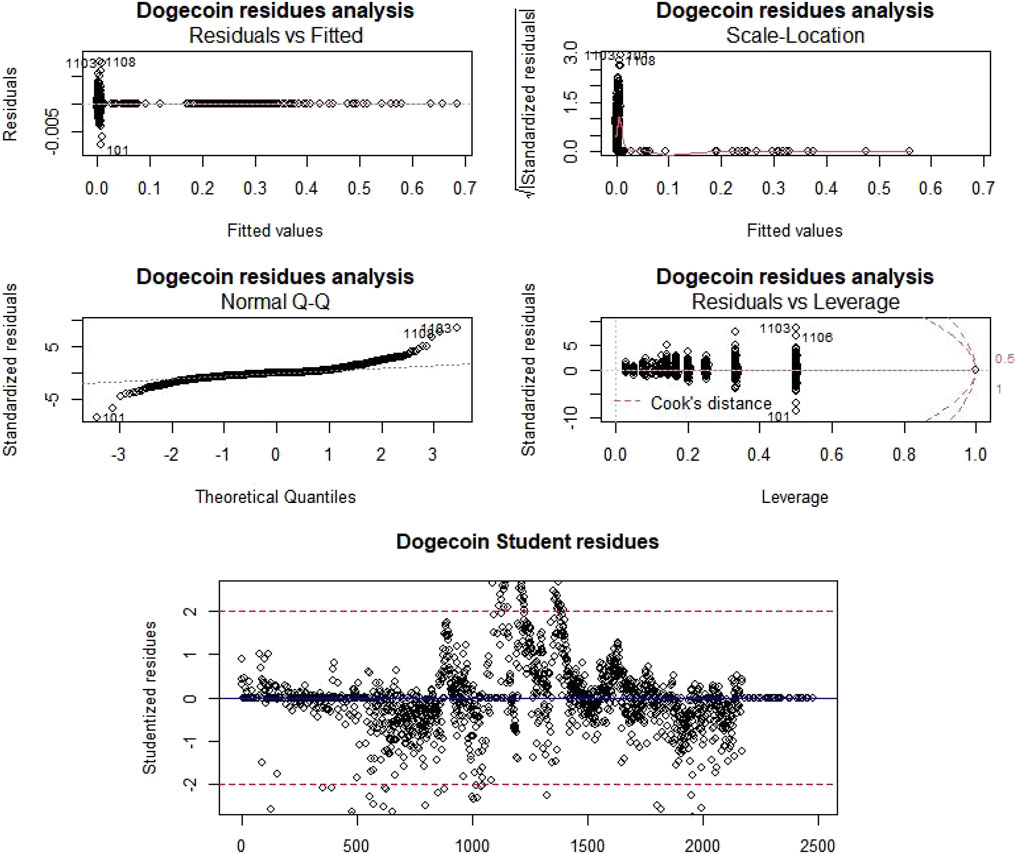
شکل 7تجزیه و تحلیل باقیمانده Dogecoin و تشخیص دور.
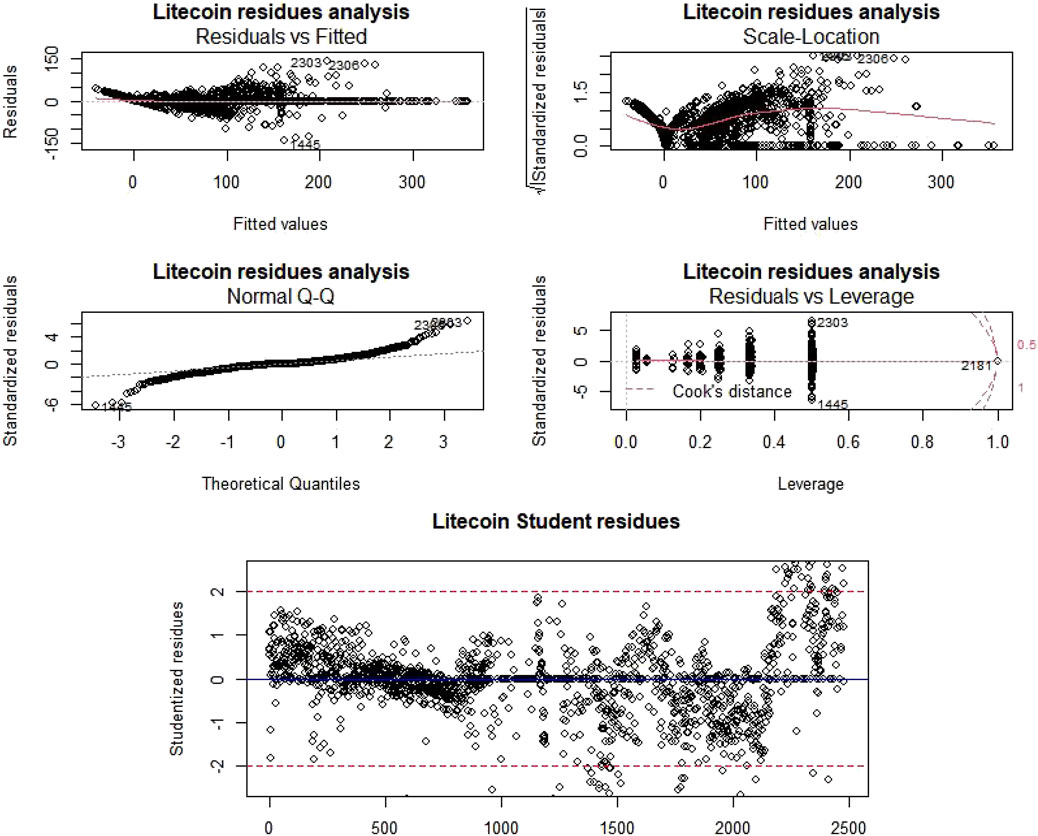
شکل 8 . تجزیه و تحلیل باقیمانده Litecoin و تشخیص دور.

جدول 4تجزیه و تحلیل جدول واریانس Cryptos.
As the Pr (>ج) همیشه تحت آستانه آلفا (0. 05) است ، ما فرضیه تهی را رد می کنیم و بنابراین ، روندهای غیر تهی برای قیمت Litecoin و Dogecoin وجود دارد. علاوه بر این ، در مورد داده های باقیمانده در مقابل مطالعات داده های مناسب ، امتیاز به طور تصادفی در اطراف محور افقی y = 0 توزیع می شود و هیچ روند را نشان نمی دهد. نمودارهای "مکان-مکان" روندهای جزئی را نشان می دهد که با این حال ، آشکار نیست. طبق نمودارهای "QQ-NORM" ، باقیمانده ها به طور معمول توزیع می شوند. آخرین نمودار ، "باقیمانده در مقابل اهرم" ، اهمیت هر نقطه در رگرسیون را برجسته می کند. همانطور که می بینیم ، در هر نمونه تنها یک نقطه با فاصله آشپز بیشتر از 1 وجود دارد (باعث می شود داده ها با آن نقطه ناچیز مشکوک شوند).
ما همچنین نقاط مظنون را شناسایی کرده ایم ، که نقاطی هستند که باقیمانده دانشجویی از آن بیشتر از 2 با ارزش مطلق است و یا فاصله آشپز بیشتر از 1 است (شکل 7b ، شکل 8b). در حالت دوم ، این نقطه بسیار/بیش از حد به تعیین ضرایب مدل در مقایسه با دیگران کمک می کند. با این حال ، هیچ روش یک اندازه مناسب برای مقابله با این نوع بخیه ها وجود ندارد. بنابراین ، یک مدل سازی یادگیری ماشین ، همانطور که در آن زمان انجام شد ، لازم است.
آریما
همانطور که در روش ها آورده شده است ، مدل ARIMA مقادیر آینده را بر اساس رفتار گذشته پیش بینی می کند. ما معیارهای خاصی را برای دانستن وضعیت مدل خود پس از آموزش و از دست دادن اطلاعات در طول آموزش و انتخاب بهترین مدل در نظر گرفتیم. حداقل ضرر نشانگر آموزش بهتر است. انتخاب ها به طور خودکار با استفاده از عملکرد "Auto. arima" بسته R پیش بینی R انجام شد (Guasti Lima و Assaf Neto ، 2022).
ما حدود 0. 99 ٪ از کل داده های قیمت Litecoin/Dogecoin را برای آموزش 24،482 نمونه انتخاب کردیم که در نظر گرفتیم تمام مقادیر گذشته قیمت گذاری Litecoin/Dogecoin را پیش بینی کنیم (شکل 9). سپس ، ما خطا (معادله 10) را برای هر مقدار گذشته پیش بینی شده بر اساس مقادیر پیش بینی شده و واقعی محاسبه کردیم.
e r r o r = a b s (f o r e c a s t e d v a l u e - t e s t p r i c e) t e s t p r i c e ∗ 100. (10)
ویدیو های آموزشی فارکس...
ما را در سایت ویدیو های آموزشی فارکس دنبال می کنید
برچسب :
نویسنده : محبوب امانی
بازدید : 69
پيوندهای روزانه
خبرنامه
