- آموزش بازار سهام جهانی و بازارهای مالی
- کلیفورد شانس
- تجارت موقعیت چیست؟مزایا و مضرات تجارت موقعیت
- گزارش بازارهای جهانی - 1 مارس
- چگونه بدون پول یک کسب و کار راه اندازی کنیم
- بحث ناهار zew در بروکسل - موانع آشنا و رویکردهای جدید در سیاست جهانی آب و هوا
- بهترین سیگنال های رمزنگاری بیت کوین
- راهنمای ساده برای بهترین کیف پول Zcash در سال 2023
- tradergav. com
- Olymptrade - حساب نگهداری - پول متوقف ، ثبت نام

آخرین مطالب
امکانات وب


این که آیا شما یک سرمایه گذار در حال ردیابی نمونه کارها خود هستید ، یا یک شرکت سرمایه گذاری که به دنبال راهی برای به روز کردن کارآمدتر است ، ایجاد یک اسکریپت برای تهیه اطلاعات بازار سهام می تواند باعث صرفه جویی در وقت و انرژی شما شود.
در این آموزش ، ما یک اسکریپت را برای ردیابی چندین قیمت سهام ایجاد خواهیم کرد ، آنها را در یک فایل CSV با خواندن آسان سازماندهی می کنیم که خود را با فشار یک دکمه به روز می کند و صدها نقطه داده را در چند ثانیه جمع می کند.
ساختن یک اسکرابر بازار سهام با درخواست و سوپ زیبا
برای این تمرین ، ما برای استخراج قیمت سهام به روز از مایکروسافت ، کوکاکولا و نایک و ذخیره آن در یک پرونده CSV ، سرمایه گذاری می کنیم. ما همچنین به شما نشان خواهیم داد که چگونه می توانید از ربات خود در برابر مسدود شدن مکانیسم ها و تکنیک های ضد خراش با استفاده از Scraprapi محافظت کنید.
توجه: این اسکریپت برای خراش داده های بازار سهام حتی بدون ScrapRapi کار خواهد کرد ، اما بعداً برای مقیاس بندی پروژه شما بسیار مهم خواهد بود.
اگرچه ما شما را در هر مرحله از روند پیاده روی خواهیم کرد ، اما داشتن برخی از دانش در مورد کتابخانه سوپ زیبا از قبل مفید است. اگر کاملاً تازه وارد این کتابخانه هستید ، آموزش سوپ زیبای ما را برای مبتدیان بررسی کنید. این بسته بندی شده با نکات و ترفندهایی است ، و به اصول اولیه ای که باید بدانید برای تقریباً هر چیزی می پردازید.
با این کار ، اجازه دهید به کد بپردازیم تا بتوانید نحوه خراش داده های بازار سهام را یاد بگیرید.
1. تنظیم پروژه ما
برای شروع ، ما پوشه ای با نام "Scraper-Stock-Project" ایجاد خواهیم کرد و آن را از VScode باز می کنیم (می توانید از هر ویرایشگر متن مورد نظر خود استفاده کنید). در مرحله بعد ، ما یک ترمینال جدید را باز خواهیم کرد و دو وابستگی اصلی خود را برای این پروژه نصب خواهیم کرد:
- PIP3 BS4 را نصب کنید
- PIP3 درخواست ها را نصب کنید
پس از آن ، ما یک پرونده جدید به نام "StockData-scraper. py" ایجاد خواهیم کرد و وابستگی های خود را به آن وارد می کنیم.
درخواست های واردات از BS4 را به صورت زیبا وارد کنید
با درخواست ها ، ما می توانیم یک درخواست HTTP را برای بارگیری پرونده HTML که سپس برای تجزیه و تحلیل به BeautifulSoup منتقل می شود ، ارسال کنیم. بنابراین بیایید با ارسال درخواست به صفحه سهام نایک ، آن را آزمایش کنیم:
url = 'https://www. investing. com/equities/nike' صفحه = prints. get (url) چاپ (page. status_code)
با چاپ کد وضعیت متغیر صفحه (که درخواست ما است) ، ما مطمئناً می دانیم که آیا می توانیم صفحه را خراب کنیم یا نه. کدی که ما به دنبال آن هستیم 200 است ، به این معنی که این یک درخواست موفق بود.

موفقیت! قبل از حرکت ، ما پاسخ ذخیره شده در صفحه را به سوپ زیبا برای تجزیه می کنیم:
سوپ = زیبا (page. text ، 'html. parser')
شما می توانید از هر تجزیه و تحلیل مورد نظر خود استفاده کنید ، اما ما با html. parser می رویم زیرا این یکی است که ما دوست داریم.
2. ساختار HTML وب سایت را بازرسی کنید (Investing. com)
قبل از شروع کار ، اجازه دهید https://www. investing. com/equities/nike در مرورگر خود را باز کنیم تا بیشتر با وب سایت آشنا شویم.
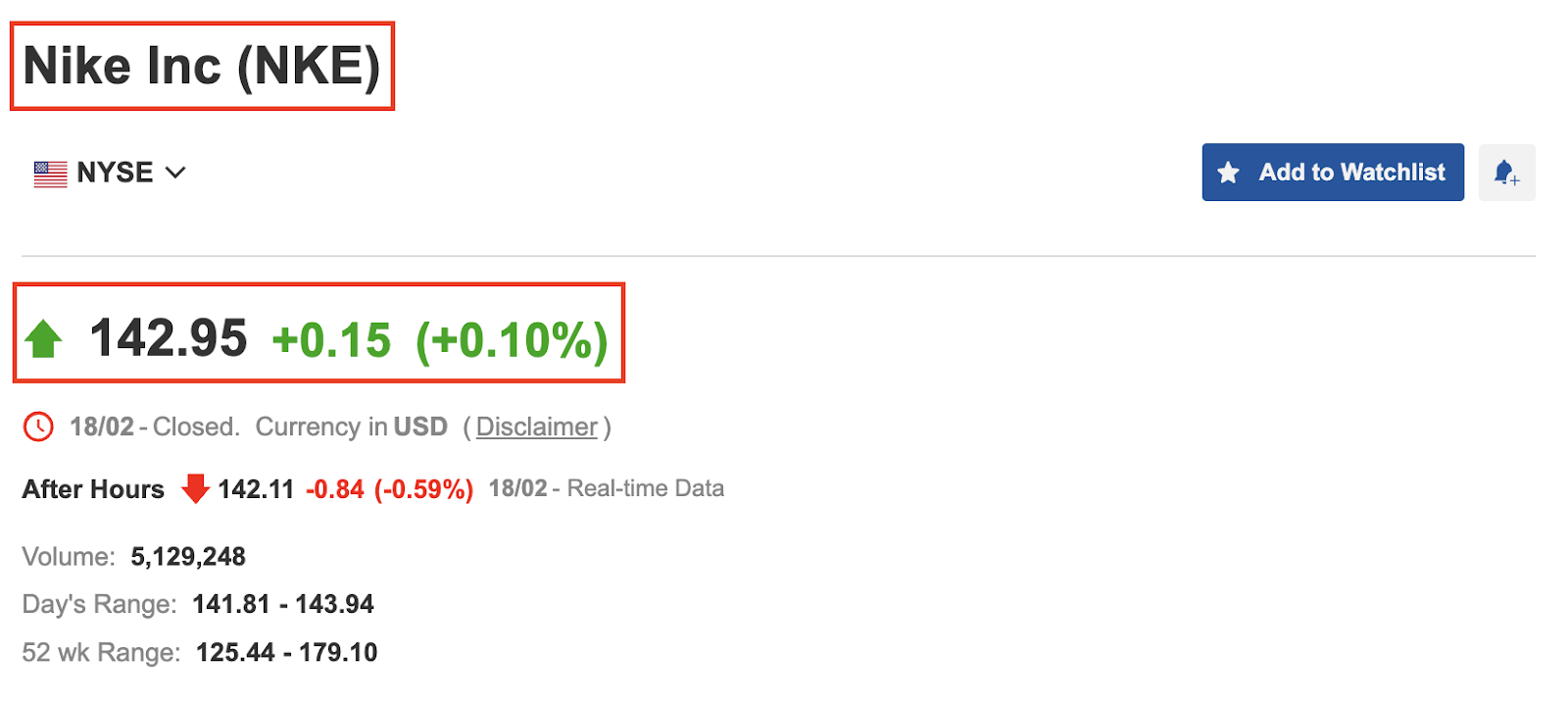
همانطور که در تصویر بالا مشاهده می کنید ، صفحه نام ، نماد سهام ، قیمت و تغییر قیمت شرکت را نشان می دهد. در این مرحله ، ما سه سوال برای پاسخ دادن داریم:
- آیا داده ها با JavaScript تزریق می شوند؟
- از چه ویژگی هایی می توان برای انتخاب عناصر استفاده کرد؟
- آیا این ویژگی ها در تمام صفحات سازگار هستند؟
برای جاوا اسکریپت بررسی کنید
روش های مختلفی برای تأیید اینکه آیا برخی از اسکریپت ها یک قطعه از داده ها را تزریق می کنند وجود دارد ، اما ساده ترین راه کلیک راست ، مشاهده منبع صفحه است.
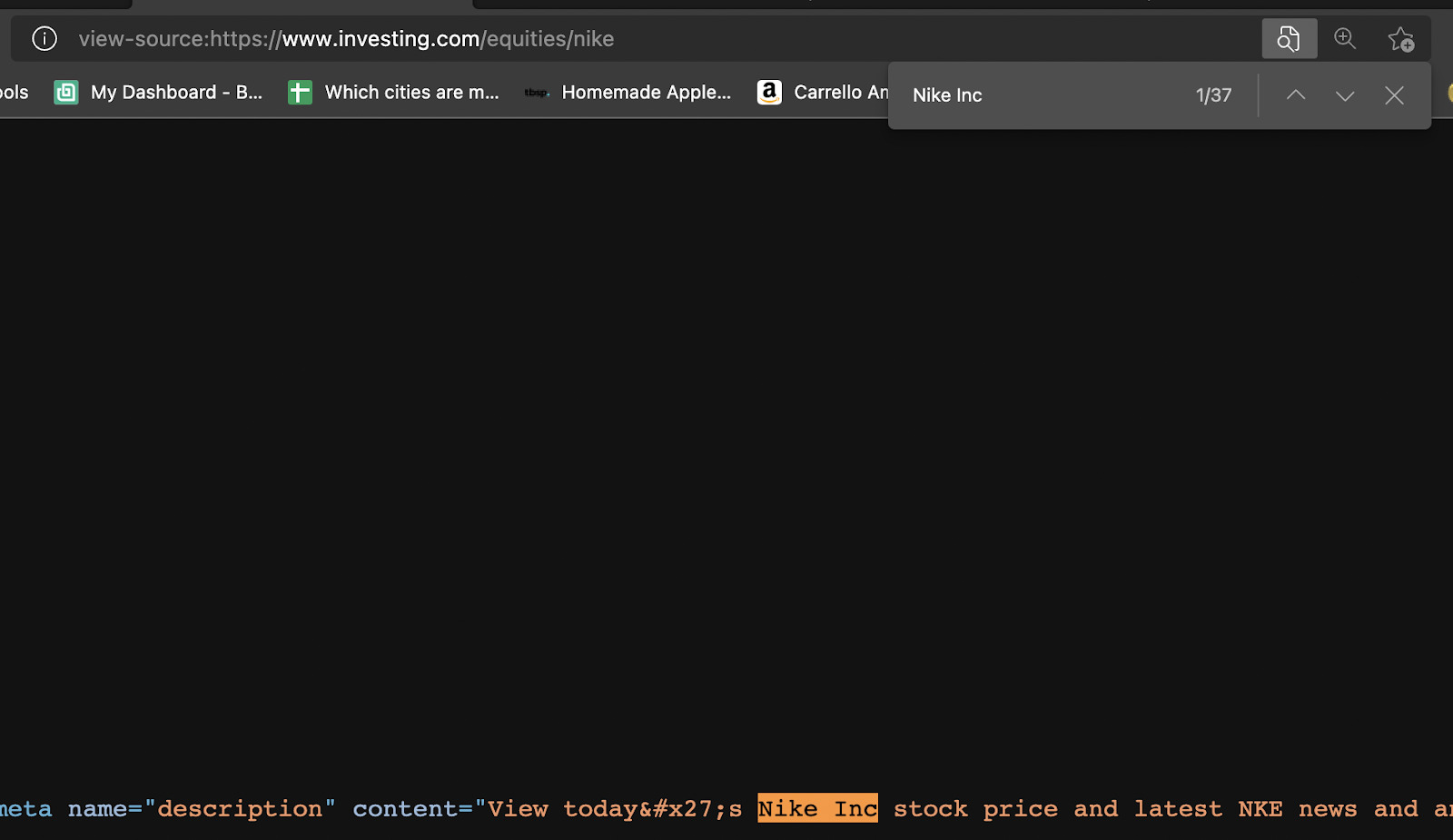
به نظر می رسد هیچ جاوا اسکریپت وجود ندارد که بتواند به طور بالقوه در خراش ما دخالت کند. بعد ما W را برای بقیه اطلاعات انجام خواهیم داد. ما JavaScript اضافی را پیدا نکردیم که خوبیم برویم.
توجه: بررسی JavaScript مهم است زیرا درخواست ها نمی توانند JavaScript را اجرا کنند یا با وب سایت تعامل داشته باشند ، بنابراین اگر اطلاعات در پشت اسکریپت است ، ما باید مانند Selenium از ابزارهای دیگر برای استخراج آن استفاده کنیم.
انتخاب انتخاب کنندگان CSS
اکنون بیایید HTML سایت را بازرسی کنیم تا ویژگی هایی را که می توانیم برای انتخاب عناصر استفاده کنیم ، شناسایی کنیم.

استخراج نام شرکت و نماد سهام نسیم خواهد بود. ما فقط باید برچسب H1 را با کلاس ‘TEXT-2XL FONT-SEMIBOLD INSTRUMING-HEADER_TITLE__GTWDV موبایل هدف قرار دهیم: MB-2.
با این حال ، قیمت ، تغییر قیمت و تغییر درصد در دهانه های مختلف از هم جدا می شود.
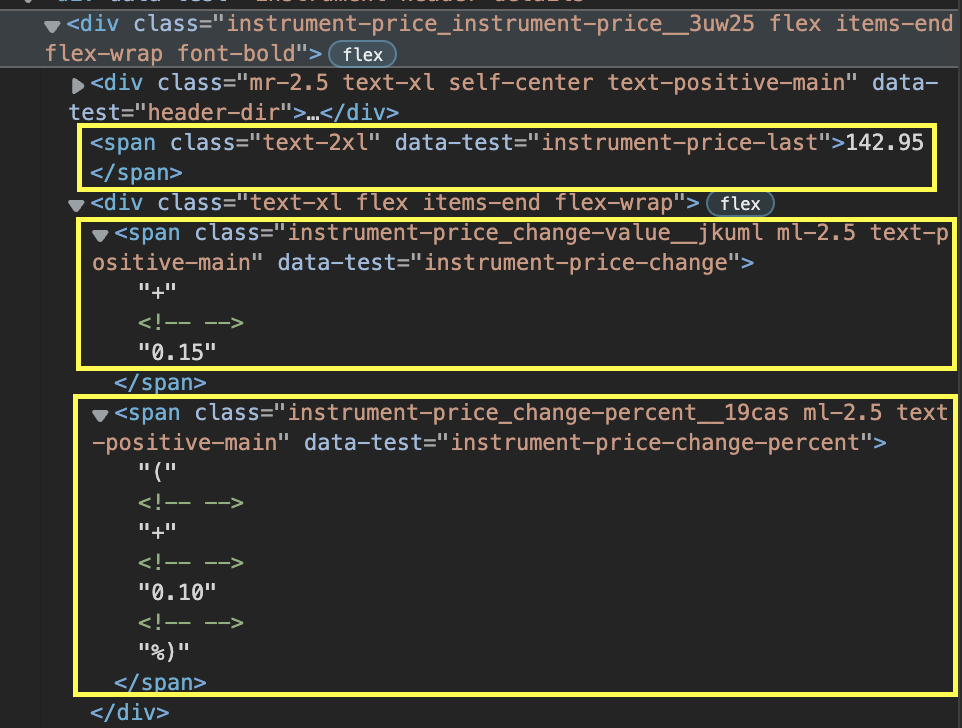
علاوه بر این ، بسته به اینکه تغییر مثبت یا منفی است ، کلاس عنصر تغییر می کند ، بنابراین حتی اگر هر دهانه را با استفاده از ویژگی کلاس خود انتخاب کنیم ، هنوز هم مواردی وجود خواهد داشت که کار نکند.
خبر خوب این است که ما یک ترفند کوچک برای بیرون آمدن آن داریم. از آنجا که سوپ زیبا یک درخت تجزیه شده را برمی گرداند ، اکنون می توانیم به درخت حرکت کنیم و عنصری را که می خواهیم انتخاب کنیم ، حتی اگر کلاس CSS دقیقی نداریم.
کاری که ما در این سناریو انجام خواهیم داد این است که در سلسله مراتب بالا می رود و یک پدر و مادر را پیدا می کنیم که می توانیم از آن سوء استفاده کنیم. سپس می توانیم از Find_All ("Span") استفاده کنیم تا لیستی از تمام عناصر حاوی برچسب Span را تهیه کنیم - که می دانیم از داده های هدف ما استفاده می کند. و از آنجا که این یک لیست است ، اکنون می توانیم به راحتی آن را حرکت دهیم و موارد مورد نیاز خود را انتخاب کنیم.
بنابراین در اینجا اهداف ما وجود دارد:
اکنون برای یک تست:
چاپ ("بارگیری:" ، URL) چاپ (شرکت ، قیمت ، تغییر)
و این نتیجه است:

3. چندین سهام را خراش دهید
اکنون که تجزیه کننده ما در حال کار است ، اجازه دهید این را مقیاس کنیم و چندین سهام را خراب کنیم. از این گذشته ، یک اسکریپت برای ردیابی فقط یک داده سهام احتمالاً بسیار مفید نخواهد بود.
ما می توانیم با ایجاد لیستی از URL ها و حلقه زدن از طریق آنها برای خروجی داده ها ، چندین صفحه را تجزیه کرده و چندین صفحه را خراش دهیم.
urls = ['https://www. investing. com/equities/nike' ، 'https://www. investing. com/equities/coca-cola-co' ، 'https://www. investing. com/سهام/Microsoft-Corp '،] برای URL در URL ها: صفحه = درخواست ها. سوپ. ('div' ،) . find_all ('span') [0] . text change = سوپ. find ('div' ،) . find_all ('span') [2] چاپ متن ("بارگیری:"، url) چاپ (شرکت ، قیمت ، تغییر)
نتیجه پس از اجرای آن است:
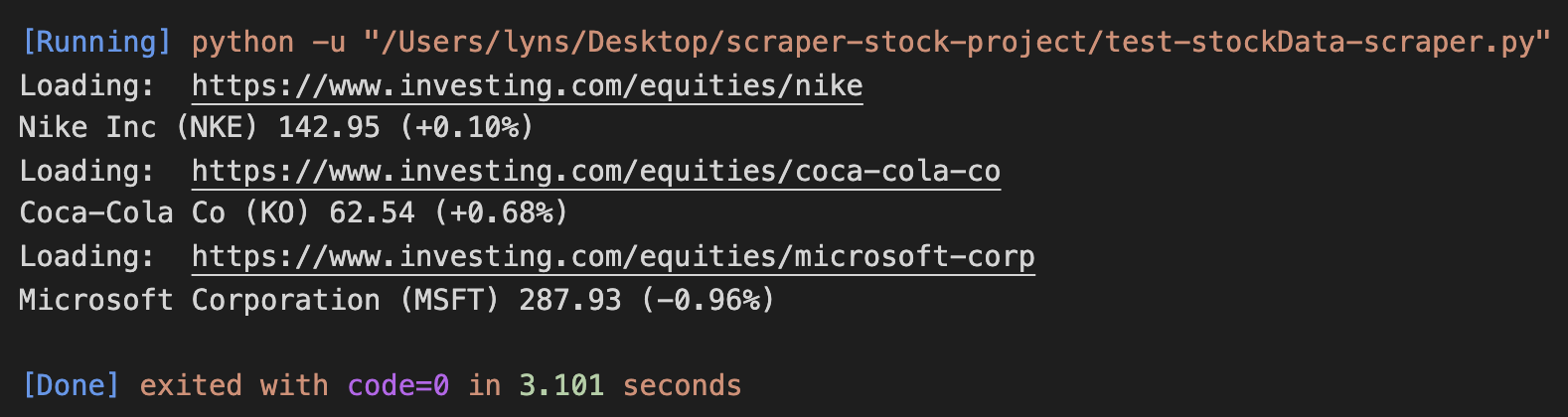
عالی ، در سراسر صفحه کار می کند!
ما می توانیم بیشتر و بیشتر صفحات را به لیست اضافه کنیم اما در نهایت ، ما به یک جاده بزرگ برخورد خواهیم کرد: تکنیک های ضد گشت و گذار.
4- ادغام Scraprapi برای رسیدگی به چرخش IP و Capchas
همه وب سایت ها دوست ندارند خراشیده شوند و به یک دلیل خوب. هنگام خراش دادن یک وب سایت ، باید در نظر داشته باشیم که ما به آن ترافیک می فرستیم و اگر مراقب نباشیم ، می توانیم پهنای باند را که وب سایت برای بازدید کنندگان واقعی دارد یا حتی افزایش هزینه های میزبانی برای مالک را محدود کنیم. گفته می شود ، تا زمانی که به بهترین شیوه های مربوط به خراش وب احترام بگذاریم ، ما هیچ مشکلی در پروژه های خود نخواهیم داشت ، و ما سایت هایی را ایجاد نمی کنیم که ما در حال حل و فصل هستیم.
با این حال ، تمایز بین مشاغل اخلاقی و مواردی که سایت های آنها را می شکند ، برای مشاغل دشوار است. به همین دلیل ، بیشتر سرورها به سیستم های مختلفی مانند مجهز خواهند شد
- پروفایل رفتار مرورگر
- کاپچا
- نظارت بر تعداد درخواست ها از یک آدرس IP در یک دوره زمانی
این اقدامات به منظور تشخیص رباتها و جلوگیری از دسترسی آنها به وب سایت برای روزها ، هفته ها یا حتی برای همیشه طراحی شده است.
به جای اینکه همه این سناریوها را به صورت جداگانه اداره کنیم ، ما فقط دو خط کد اضافه خواهیم کرد تا درخواست های ما از طریق سرورهای Scraprapi عبور کنند و همه چیز را برای ما خودکار کنیم.
ابتدا ، برای دسترسی به کلید API و 5000 اعتبار API رایگان برای پروژه ما ، یک حساب Scraprapi رایگان ایجاد می کنیم.
اکنون ما آماده هستیم تا یک متغیر جدید پارامز را به حلقه خود اضافه کنیم تا کلید و URL هدف خود را ذخیره کنیم و از urlencode برای ساخت URL استفاده کنیم که برای ارسال درخواست در متغیر صفحه استفاده خواهیم کرد.
params = page = Request. Get ('http://api. scraperapi. com/' ، params = urlencode (پارامس))
اوهو ما نمی توانیم فراموش کنیم که وابستگی جدید خود را به بالای پرونده اضافه کنیم:
از Urllib. Parse urlencode واردات
اکنون هر درخواستی از طریق Scraprapi ارسال می شود ، که به طور خودکار IP ما را پس از هر درخواست ، به سمت CAPCHA ها می چرخاند و از یادگیری ماشین و تجزیه و تحلیل آماری استفاده می کند تا بهترین هدرها را برای اطمینان از موفقیت تعیین کند.
نکته سریع: Scraprapi همچنین به ما امکان می دهد با تنظیم "رندر" یک سایت پویا را خراش دهیم: به عنوان یک پارامتر در متغیر پارامس ما درست است. Scraprapi قبل از ارسال پاسخ ، صفحه را ارائه می دهد.
5. داده ها را در یک پرونده CSV ذخیره کنید
برای ذخیره داده های خود در یک فایل CSV با استفاده آسان ، به سادگی این سه خط را بین لیست URL و حلقه خود اضافه کنید:
FILE = OPEN ('STOCKPRICES. CSV' ، 'W') نویسنده = CSV. Writer (File) Writer. Writerow (['شرکت' ، 'قیمت' ، 'تغییر']) =
این یک فایل CSV جدید ایجاد می کند و آن را به نویسنده ما (تنظیم شده در متغیر نویسنده) منتقل می کند تا ردیف اول را با عنوان های ما اضافه کند.
اضافه کردن آن در خارج از حلقه ضروری است ، یا این پرونده را پس از خراش دادن هر صفحه ، بازنویسی می کند ، اساساً داده های قبلی را پاک می کند و یک فایل CSV را فقط با داده های آخرین URL از لیست ما به ما می دهد.
علاوه بر این ، برای نوشتن داده های خراشیده باید خط دیگری به حلقه خود اضافه کنیم:
Writer. Writerow ([Company. encode ('UTF-8') ، Price. encode ('UTF-8') ، Change. encode ('UTF-8')])
و یک مورد دیگر در خارج از حلقه برای بستن پرونده:
file. close ()
6. کد تمام شده: اسکریپت داده های بازار سهام
شما آن را ساخته اید! اکنون می توانید از این اسکریپت با کلید API خود استفاده کنید و به همان تعداد سهام که می خواهید خراش دهید اضافه کنید:
#DENTENENTIES درخواست های واردات از BS4 واردات CSV را وارد می کند. سهام/coca-cola-co '،' https://www. investing. com/equities/microsoft-corp '،] #Starting پرونده پرونده CSV ما = باز (' sockprices. csv '،' w ') نویسنده = CSV. Writer (File) Writer. Writerow (["شرکت" ، "قیمت" ، "تغییر"]) #looping از طریق لیست ما برای URL در URL ها: #ارسال درخواست ما از طریق ScraperApi Params = Page = Request. get ('http://api. scraperapi. com/ '، params = urlencode (پارامترها)) #سوپ تجزیه کننده شما = زیبا (page. text ،' html. parser ') شرکت = سوپ. (' h1 '،).. find ('div' ،) . find_all ('span') [0] . text change = سوپ. find ('div' ،) . find_all ('span') [2]چاپ ('بارگیری:' ، url) چاپ (شرکت ، قیمت ، تغییر) #نوشتن داده ها به نویسنده پرونده CSV ما. writerrow ([company. encode ('utf-8') ، price. encode ('utf-8') ، change. encode ('utf-8')]) file. close ()
بسته بندی: ملاحظات هنگام اجرای اسکرابر داده های بازار سهام خود
باید به یاد داشته باشید که بورس سهام همیشه باز نیست. به عنوان مثال ، اگر داده های بورس اوراق بهادار NYC را ضبط می کنید ، ساعت 5 بعد از ظهر EST در روزهای جمعه بسته می شود و روز دوشنبه ساعت 9:30 صبح باز می شود. بنابراین هیچ نکته ای برای اجرای اسکرابر خود در آخر هفته وجود ندارد. همچنین در ساعت 4 بعد از ظهر بسته می شود تا بعد از آن هیچ تغییری در قیمت مشاهده نکنید.

متغیر دیگر که باید در نظر داشته باشید این است که چند بار نیاز به به روزرسانی داده ها دارید. بی ثبات ترین زمان برای بورس اوراق بهادار زمان باز و بسته شدن است. بنابراین ممکن است کافی باشد که فیلمنامه خود را ساعت 9:30 صبح ، ساعت 11 صبح و ساعت 4:30 بعد از ظهر اجرا کنید تا ببینید که چگونه سهام بسته می شود. افتتاح روز دوشنبه نیز برای نظارت بر بسیاری از معاملات در این مدت بسیار مهم است.
بر خلاف بازارهای دیگر مانند فارکس ، بازار سهام به طور معمول نوسانات دیوانه کننده ای را ایجاد نمی کند. گفته می شود ، اغلب اوقات اخبار و تصمیمات تجاری می تواند به شدت بر قیمت سهام تأثیر بگذارد - سهام متا را سقوط کند یا افزایش قیمت سهم GameStop را به عنوان نمونه برساند - بنابراین خواندن اخبار مربوط به سهام مورد نظر شما بسیار مهم است.
ما امیدواریم که این آموزش به شما کمک کند تا داده های بازار سهام خود را بسازید ، یا حداقل شما را در جهت درست نشان دهد. در یک آموزش آینده ، ما در بالای این پروژه برای ایجاد یک اسکرابر داده سهام در زمان واقعی برای نظارت بر سهام خود ایجاد خواهیم کرد ، بنابراین برای آن با ما همراه باشید!
تا دفعه بعد ، خراش مبارک!
ویدیو های آموزشی فارکس...
ما را در سایت ویدیو های آموزشی فارکس دنبال می کنید
برچسب :
نویسنده : محبوب امانی
بازدید : 38
پيوندهای روزانه
خبرنامه
